网络面试要点整理#
标签(空格分隔): tcp udp socket 网络
tcp为什么是三次握手#
1
2
3
4
|
TCP 建立连接时通过三次握手可以有效地避免历史错误连接的建立,减少通信双方不必要的资源消耗,三次握手能够帮助通信双方获取初始化序列号,它们能够保证数据包传输的不重不丢,还能保证它们的传输顺序,不会因为网络传输的问题发生混乱,到这里不使用『两次握手』和『四次握手』的原因已经非常清楚了:
『两次握手』:无法避免历史错误连接的初始化,浪费接收方的资源;
『四次握手』:TCP 协议的设计可以让我们同时传递 ACK 和 SYN 两个控制信息,减少了通信次数,所以不需要使用更多的通信次数传输相同的信息;
|
三次握手流程#

1
2
|
刚开始客户端处于 Closed 的状态,服务端处于 Listen 状态。
客户端发送一个 SYN (Synchronize) 标志设为1 的包,指明客户端要连接服务器端的接口,发送完毕后,客户端进入 SYN_SENT 状态 服务器发回确认包 (ACK) 应答,即 SYN标志位和ACK标志位均为1。服务器端选择自己ISN序列号(为防止固定值可能被攻击,而使用相关的算法得到的一个随机序列号),放到 Seq 域里,同时将确认序号(Acknowledgement Number)设置为客户的 ISN 加1,即X+1。 发送 完毕后,服务器端进入 SYN_RCVD 状态。 客户端再次发送确认包(ACK),SYN 标志位为0,ACK 标志位为1,并且把服务器发来 ACK 的 序号字段+1,放在确定字段中发送给对方,并且在数据段放写ISN的+1, 最后双方都会进入established状态
|
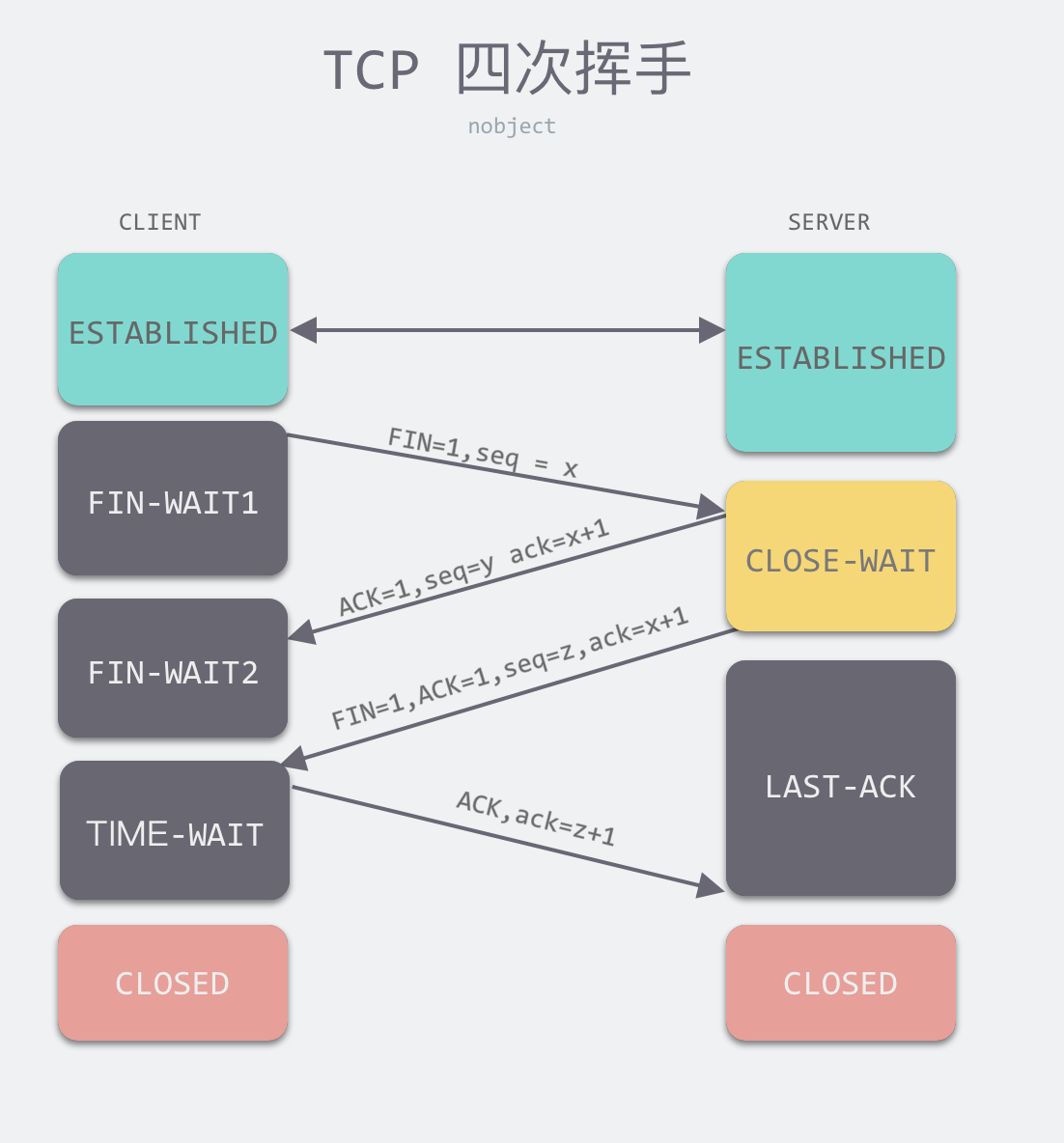
四次挥手流程#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
刚开始双方都处于 ESTABLISHED 状态,假如是客户端先发起关闭请求。四次挥手的过程如下:
第一次挥手:客户端发送一个 FIN 报文,报文中会指定一个序列号。此时客户端处于 FIN_WAIT1 状态。
即发出连接释放报文段(FIN=1,序号seq=u),并停止再发送数据,主动关闭TCP连接,进入FIN_WAIT1(终止等待1)状态,等待服务端的确认。
第二次挥手:服务端收到 FIN 之后,会发送 ACK 报文,且把客户端的序列号值 +1 作为 ACK 报文的序列号值,表明已经收到客户端的报文了,此时服务端处于 CLOSE_WAIT 状态。
即服务端收到连接释放报文段后即发出确认报文段(ACK=1,确认号ack=u+1,序号seq=v),服务端进入CLOSE_WAIT(关闭等待)状态,此时的TCP处于半关闭状态,客户端到服务端的连接释放。客户端收到服务端的确认后,进入FIN_WAIT2(终止等待2)状态,等待服务端发出的连接释放报文段。
第三次挥手:如果服务端也想断开连接了,和客户端的第一次挥手一样,发给 FIN 报文,且指定一个序列号。此时服务端处于 LAST_ACK 的状态。
即服务端没有要向客户端发出的数据,服务端发出连接释放报文段(FIN=1,ACK=1,序号seq=w,确认号ack=u+1),服务端进入LAST_ACK(最后确认)状态,等待客户端的确认。
第四次挥手:客户端收到 FIN 之后,一样发送一个 ACK 报文作为应答,且把服务端的序列号值 +1 作为自己 ACK 报文的序列号值,此时客户端处于 TIME_WAIT 状态。需要过一阵子以确保服务端收到自己的 ACK 报文之后才会进入 CLOSED 状态,服务端收到 ACK 报文之后,就处于关闭连接了,处于 CLOSED 状态。
即客户端收到服务端的连接释放报文段后,对此发出确认报文段(ACK=1,seq=u+1,ack=w+1),客户端进入TIME_WAIT(时间等待)状态。此时TCP未释放掉,需要经过时间等待计时器设置的时间2MSL后,客户端才进入CLOSED状态。
收到一个FIN只意味着在这一方向上没有数据流动。客户端执行主动关闭并进入TIME_WAIT是正常的,服务端通常执行被动关闭,不会进入TIME_WAIT状态。
|
为什么需要四次挥手#
1
2
3
|
因为当服务端收到客户端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。
但是关闭连接时,当服务端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉客户端,“你发的FIN报文我收到了”。只有等到我服务端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四次挥手。
|
time_wait状态为什么需要等待2MSL#
1
2
|
1. 防止延迟的数据段被其他使用相同源地址、源端口、目的地址以及目的端口的 TCP 连接收到;
2. 确保最后一个确认报文段能够到达。如果 被动关闭端 没收到 主动关闭端 发送来的确认报文段,那么就会重新发送连接释放请求报文段,主动端等待一段时间就是为了处理这种情况的发生。
|
time_wait状态过多怎么办#
1
2
|
使用 SO_LINGER 选项并设置暂存时间 l_linger 为 0,在这时如果我们关闭 TCP 连接,内核就会直接丢弃缓冲区中的全部数据并向服务端发送 RST 消息直接终止当前的连接
tcp_tw_reuse : 开启后,可直接回收超过1s的 time_wait 状态的连接。
|
用户在网页上输入一个url后发生了什么#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
0、浏览器本地缓存匹配;
1、本地hosts映射对比;
2、本地dns缓存解析;
3、远程dns解析获得服务器ip地址;
4、浏览器发送tcp连接请求包(syn);
5、请求包经过传输层、网络层、数据链路层封装通过网卡到达路由器;
6、路由器转发数据包到所属运营商服务器;
7、运营商服务器通过寻址最短路径通过中继节点到达指定ip地址;
8、服务器端可能存在反向代理或者负载均衡,都是直接转发请求至上游服务器,当然也可以制定安全防御规则直接丢弃请求包;
9、上游服务器收到连接请求,在自身可用的情况下,返回(syn+ack);
10、浏览器校验ack,再次发送(syn+ack);
11、服务器校验ack切换连接状态至established,然后根据请求传输数据包;
12、当transform-encoding为chunked时,浏览器开始渲染页面;
13、四次挥手,连接关闭;
14、渲染数据完成。
|
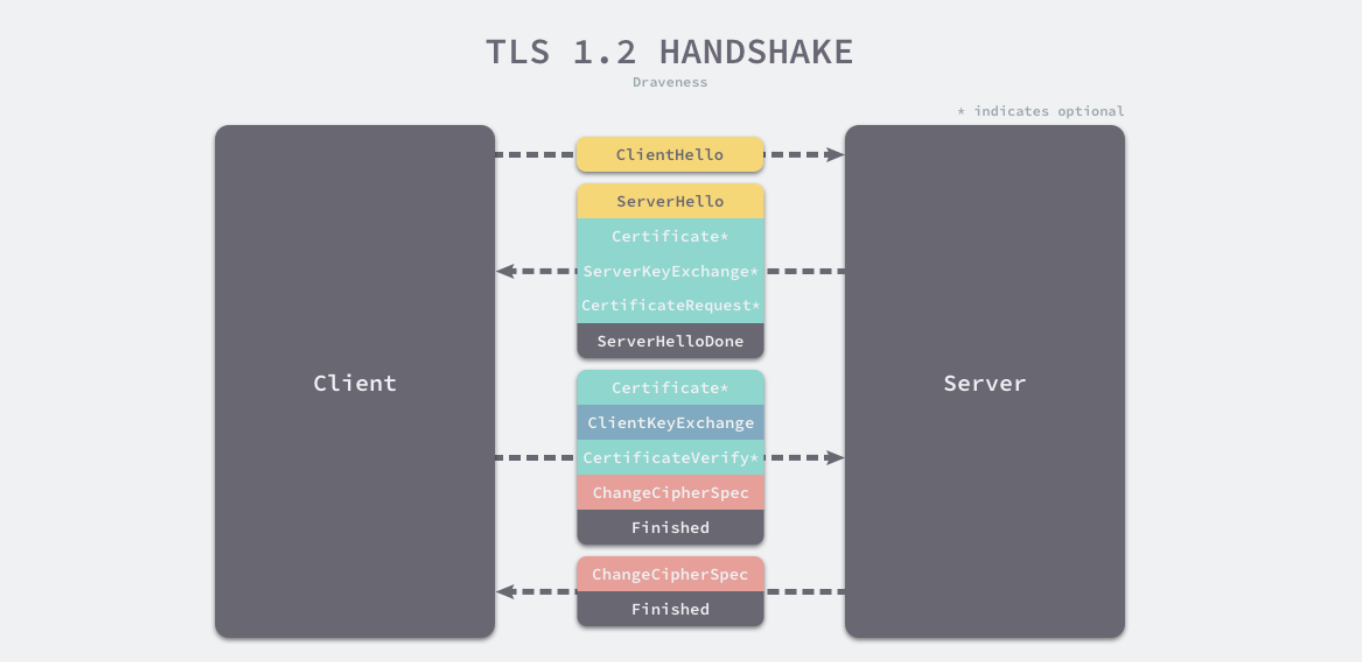
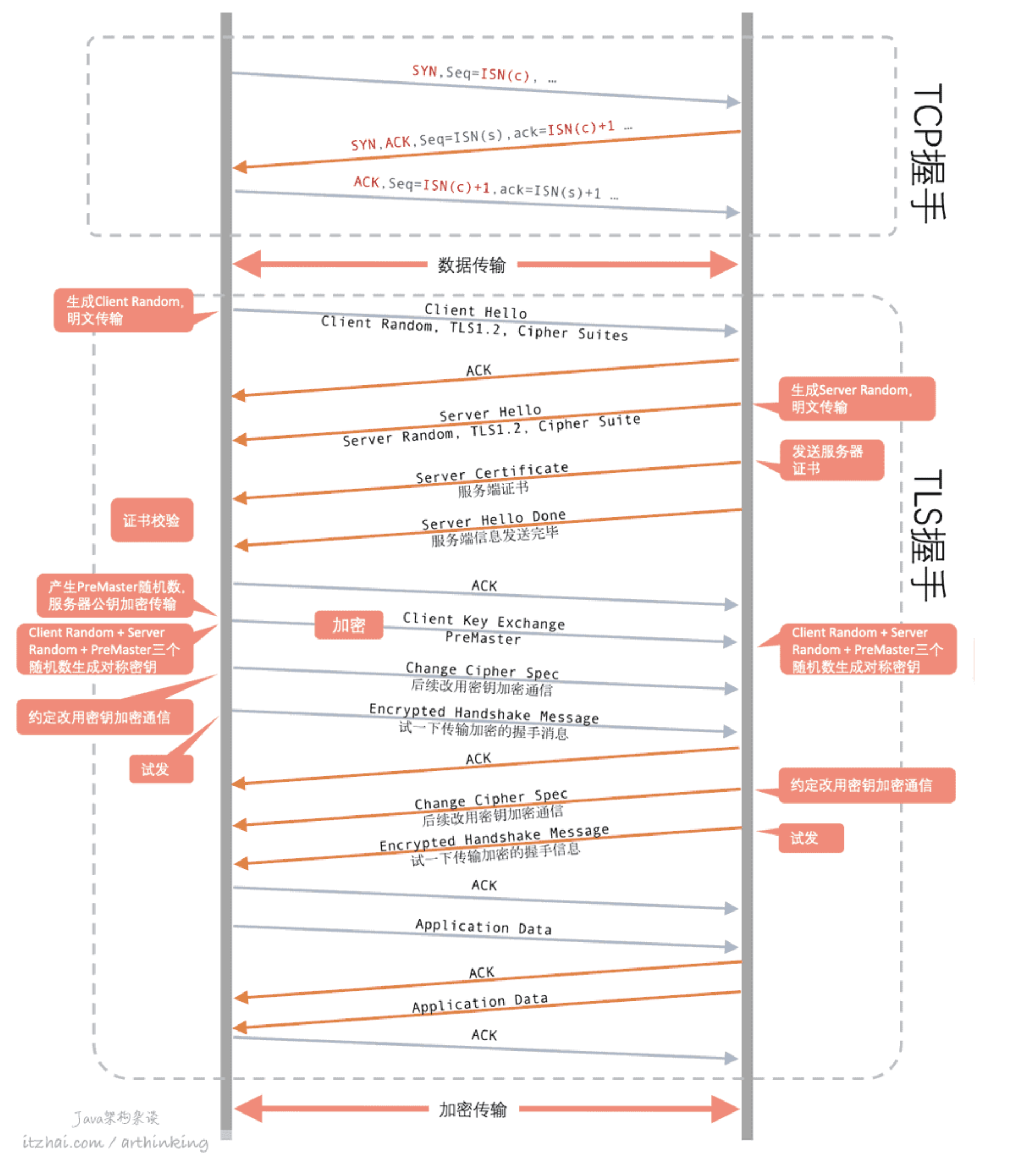
https的过程#
https的4次握手图:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
首先,http会进行三次握手,握手成功后,会进行https的4次握手,总共有7次握手
1. 客户端向服务端发送 Client Hello 消息,其中携带客户端支持的协议版本、加密算法、压缩算法以及客户端生成的随机数;
2.服务端收到客户端支持的协议版本、加密算法等信息后;
向客户端发送 Server Hello 消息,并携带选择特定的协议版本、加密方法、会话 ID 以及服务端生成的随机数;
向客户端发送 Certificate 消息,即服务端的证书链,其中包含证书支持的域名、发行方和有效期等信息;
向客户端发送 Server Key Exchange 消息,传递公钥以及签名等信息;
向客户端发送可选的消息 CertificateRequest,验证客户端的证书;
向客户端发送 Server Hello Done 消息,通知服务端已经发送了全部的相关信息;
3. 客户端收到服务端的协议版本、加密方法、会话 ID 以及证书等信息后,验证服务端的证书;
向服务端发送 Client Key Exchange 消息,包含使用服务端公钥加密后的随机字符串,即预主密钥(Pre Master Secret);
向服务端发送 Change Cipher Spec 消息,通知服务端后面的数据段会加密传输;
向服务端发送 Finished 消息,其中包含加密后的握手信息;
4. 服务端收到 Change Cipher Spec 和 Finished 消息后;
向客户端发送 Change Cipher Spec 消息,通知客户端后面的数据段会加密传输;
向客户端发送 Finished 消息,验证客户端的 Finished 消息并完成 TLS 握手;
通过非对称加密算法交换对称加密算法的密钥,交换完成之后,在使用对称加密进行加解密传输数据。这样就保证了会话的机密性。
TLS1.3简化了握手过程,主要就是把原来两个RTT中的信息,打包成一个发送了,减少传输次数,最终只需要1个RTT就完成了信息的交换和握手。密钥交换算法废弃了RSA,更好地保证了安全性,不会因为RSA私钥泄露导致历史报文被破解的问题出现。
|
大量出现CLOSE_WAIT是因为什么#
1
2
3
4
5
6
7
8
9
|
大量time_wait的原因:
高并发短连接的服务器上会出现这样的情况,导致创建大量的tcp连接然后close,出现大量的连接出现time_wait的状态
大量close_wait的原因:
close_wait是被动关闭连接是形成的,根据TCP状态机,服务器端收到客户端发送的FIN,TCP协议栈会自动发送ACK,链接进入close_wait状态。但如果服务器端不执行socket的close()操作(即不向客户端发送FIN),状态就不能由close_wait迁移到last_ack,则系统中会存在很多close_wait状态的连接
通常,CLOSE_WAIT 状态在服务器停留时间很短,如果你发现大量的 CLOSE_WAIT 状态,那么就意味着被动关闭的一方没有及时发出 FIN 包,一般有如下几种可能:
程序问题:如果代码层面忘记了 close 相应的 socket 连接,那么自然不会发出 FIN 包,从而导致 CLOSE_WAIT 累积;或者代码不严谨,出现死循环之类的问题,导致即便后面写了 close 也永远执行不到。
响应太慢或者超时设置过小:如果连接双方不和谐,一方不耐烦直接 timeout,另一方却还在忙于耗时逻辑,就会导致 close 被延后。响应太慢是首要问题,不过换个角度看,也可能是 timeout 设置过小。包括mysql事务未提交,或者使用完未关闭等
|
502是什么?如果出现502怎么办?#
1
2
3
|
作为网关或者代理服务器去请求上游服务器时,由于上游服务器处理超时、配置错误、负载高处理请求慢,数据库死锁,服务未启动等问题导致网关服务报 502
出现502,看服务器日志查看具体原因
|
http和rpc的区别#
1
2
3
4
5
6
|
RPC 只是一种设计而已
RPC 只是一种概念、一种设计,就是为了解决 不同服务之间的调用问题, 它一般会包含有 传输协议 和 序列化协议 这两个。
但是,HTTP 是一种协议,RPC框架可以使用 HTTP协议作为传输协议或者直接使用TCP作为传输协议,使用不同的协议一般也是为了适应不同的场景。
成熟的 RPC框架还提供好了“服务自动注册与发现”、"智能负载均衡"、“可视化的服务治理和运维”、“运行期流量调度”等等功能,这些也算是选择 RPC 进行服务注册和发现的一方面原因吧!
|
TCP差错控制、流量控制,拥塞控制#
HTTP 2.0#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
HTTP/1.1的问题也是很多的,主要是连接缓慢,服务器只能按顺序响应,如果某个请求花了很长时间,就会出现请求队头阻塞,从而影响其他请求。
这个时期出现了很多各式的前端优化小技巧,当年搞过一段时间前端,也对这些技术略知一二,如:
为了增加并发请求,做域名拆分;
CSS、JS等资源内联到HTML中,或者进行资源合并;
生成精灵图,一次性传输所有小图标;
资源预取...
HTTP/2又解决了HTTP/1.1面临的大部分问题,主要有如下功能:
- 使用虚拟的流传输消息,解决了HTTP一个连接中应用层的队头阻塞的问题;
HTTP是基于请求应答模型的,在非管道传输的情况下,只要请求的应答还没有收到,同一个TCP连接的下一个请求就会被阻塞住,发不出去。如 果要能够同时发,就不得不同时创建多个TCP连接了。在HTTP/2中,由于是基于帧的发送,于是取消了这个针对单个请求的阻塞行为,而是可以在一个连接中,同时传递多个请求的数据,每个请求对应的所有数据报组成一个数据流,每个数据流都有一个独一无二的编号,帧中的Stream Identifier就是流ID表示。流与流之间是并行发送的,乱序的,而在流内发送和接收是顺序的。
- 使用了二进制协议,不再是纯文本,避免文本歧义,缩小了请求体积;
- 实现了多路复用,提高了连接的利用率,在拥塞控制方面有了更好的能力提升;
- 使用HPACK首部压缩方案压缩头部信息,大大节约了带宽;
服务器与客户端同时维护动态表与静态表头部字段,如果在表中,直接传索引值,如果不在表中,则用哈夫曼编码,可以节约带宽
- 增强了安全性,使用HTTP/2,要求必须至少用TLS1.2;
- 允许服务器主动向客户端推送数据;
|
HTTP 3.0 quic#
https://www.cnblogs.com/lsdh/p/14334141.html
1
2
3
4
5
6
7
|
HTTP/2还在草案的时候,Google又发现新的问题了,那就是由于HTTP/2依赖于TCP,TCP有什么问题,那么HTTP/2就会存在什么问题。最主要的问题还是队头阻塞问题:队头阻塞问题在应用层解决了,但是在TCP协议层并没有解决:
TCP在丢包的时候会进行重传,前面有一个包没有接收到,就只能把后面的包先放到缓冲区里面,应用层实际上是无法取数据的。也就是说HTTP / 2的多路复用的并行性对于TCP的丢失恢复机制不管用,因此丢失或者重新排序的数据报都会导致所有活动事务陷入停顿。
传输层用UDP替换掉了TCP,并在用户空间实现了一套拥塞控制算法,从而避免了TCP的队头阻塞问题。
在UDP之上,QUIC实现了连接管理、拥塞窗口、流量控制等。
|
https中间人劫持#
1
2
3
4
5
6
7
8
9
10
|
- 传统的http传输是明文传输的,导致有安全患
- 如果采用对称加密方式,因为加密算法的透明性,而且加密密钥的交换也是透明的,无法保证安全
- 如果采用非对象加密,即使采用公钥私钥解密,在相互交换公钥的时候,但如果有中间人劫持,伪装成服务端,将自己的公钥发给服务端,然后转发自己的公钥给客户端,所以在交换公钥的时候,还是会有问题
- 所以需要一个公证中心来证明该公钥就是服务端的而不是中间人的。怎么证明?
- 所以CA出现了,他是一个公证中心,服务器会将自己的信息(公钥等其他信息)通过哈希算法形成消息摘要,然后提交至CA,CA用自己的私钥加密,形成数字签名,服务器信息(原始信息,未进行哈希处理)与数字签名合并成数字证书。
- 客户端收到数字证书,用hash算法对服务器原始信息hash算法计算,数字签名用CA的公钥解密形成消息摘要,然后进行比对校验是否相等,不相等则被劫持
谁来保证CA的公钥的正确性?
客户端验证的时候,需要拿到数字证书发布机构的CA公钥,但是怎么证明这个CA公钥是正确的呢?这个时候就需要有更大的CA帮小的CA的公钥做认证了,一层一层的背书,最顶层的CA,Root CA,称为根证书,作为信任链的根,是全球皆知的的极大著名CA,这些根证书一般会内置到操作系统中。
|
tcp与udp的区别#
1
2
3
4
5
6
7
8
9
10
11
|
1、基于连接与无连接;
2、对系统资源的要求(TCP较多,UDP少);
3、UDP程序结构较简单;
4、流模式与数据报模式 ;
5、TCP保证数据正确性,UDP可能丢包;
6、TCP保证数据顺序,UDP不保证。
|
restful 与 rpc 区别#
https://zhuanlan.zhihu.com/p/34440779
epool与select的区别#
https://www.itzhai.com/articles/thoroughly-understand-io-reuse-take-you-in-depth-understanding-of-select-poll-epoll.
https://mp.weixin.qq.com/s/Qpa0qXxuIM8jrBqDaXmVNA
I/O复用(I/O multiplexing),指的是通过一个支持同时感知多个描述符的函数系统调用,阻塞在这个系统调用上,等待某一个或者几个描述符准备就绪,就返回可读条件。
简单来说多个请求复用了一个进程,这就是多路复用
select,poll,epoll系统调用可以实现此类功能功能
select#
select 实现多路复用的方式是,将已连接的 Socket 都放到一个文件描述符集合,然后调用 select 函数将文件描述符集合拷贝到内核里,让内核来检查是否有网络事件产生,
检查的方式很粗暴,就是通过遍历文件描述符集合的方式,当检查到有事件产生后,将此 Socket 标记为可读或可写,
接着再把整个文件描述符集合拷贝回用户态里,然后用户态还需要再通过遍历的方法找到可读或可写的 Socket,然后再对其处理。
对于 select 这种方式,需要进行 2 次「遍历」文件描述符集合,一次是在内核态里,一个次是在用户态里 ,而且还会发生 2 次「拷贝」文件描述符集合,先从用户空间传入内核空间,由内核修改后,再传出到用户空间中。
select 优点:
1
|
非阻塞IO直接轮训查询数据是否准备好,每次查询都要切换内核态,轮训消耗CPU。而select函数则直接把查询多个描述符的动作交给了内核,这样避免了CPU消耗和减少了内核态的切换。
|
select缺点:
1
2
3
4
|
fd_set中的bitmap是固定1024位的,也就是说最多只能监听1024个套接字。当然也可以改内核源码,不过代价比较大;
fd_set每次传入内核之后,都会被改写,导致不可重用,每次调用select都需要重新初始化fd_set;
每次调用select都需要拷贝新的fd_set到内核空间,这里会做一个用户态到内核态的切换;
拿到fd_set的结果后,应用进程需要遍历整个fd_set,才知道哪些文件描述符有数据可以处理。
|
epool#
1
2
3
4
5
6
7
8
|
epoll 通过两个方面,很好解决了 select/poll 的问题。
epoll 在内核里使用红黑树来跟踪进程所有待检测的文件描述字,把需要监控的 socket 通过 epoll_ctl() 函数加入内核中的红黑树里,红黑树是个高效的数据结构,
增删查一般时间复杂度是 O(logn),通过对这棵黑红树进行操作,这样就不需要像 select/poll 每次操作时都传入整个 socket 集合,只需要传入一个待检测的 socket,减少了内核和用户空间大量的数据拷贝和内存分配。
第二点, epoll 使用事件驱动的机制,内核里维护了一个链表来记录就绪事件,当某个 socket 有事件发生时,通过回调函数内核会将其加入到这个就绪事件列表中,
当用户调用 epoll_wait() 函数时,只会返回有事件发生的文件描述符的个数,不需要像 select/poll 那样轮询扫描整个 socket 集合,大大提高了检测的效率。
|
优点:
1
2
3
4
|
epoll每次调用epoll_wait的时候,不像poll调用一样,每次都要传递结构体到内核空间,而是复用一个内核的epoll实例结构体,通过epfd进行引用,从而减小了系统开销;
epoll底层是套接字一旦有事件,就调用回调立刻通知epoll实例,可以尽早的准备好事件就绪队列,执行epoll_wait的时候相应的更快;
epoll底层基于红黑树维护兴趣事件列表,这样每次套接字有新事件触发回调的时候,可以更快的找到套接字的epitem进行后续的处理;
提供了性能更佳的边缘触发机制。
|
缺点:
1
2
3
|
它还不是真正的异步IO,还是要应用进程调用IO函数的时候,才把数据从内核拷贝到应用进程。
关于异步IO,我们下一节会继续探讨。
|
边缘触发:
1
2
|
当一个添加到epoll实例的epoll_event设置为EPOLLET边缘触发(edge-triggered)之后,如果后续有描述符的事件准备好了,调用epoll_wait就会把对应的epoll_event返回给应用进程,
注意,在边缘触发模式下,只会返回已准备好的描述符的epoll_evnet一次,也就是说程序只有一次的处理机会。
|
水平触发:
1
2
3
|
当把要添加到epoll实例的epoll_event设置为EPOLLLT条件触发(level-triggered)时,只要已准备好的描述符没有被处理完,下一次调用epoll_wait的时候,还是会继续返回给应用进程处理。这是系统默认处理方式。
EPOLLET边缘触发的效率要比EPOLLLT高效,因为对于每个准备就绪的套接字,只会通知应用进程一次,但是这也要求程序员必须小心处理,不会留多次机会给你去补偿处理套接字。
|
总结:
1
2
3
|
如果使用边缘触发模式,I/O 事件发生时只会通知一次,而且我们不知道到底能读写多少数据,所以在收到通知后应尽可能地读写数据,以免错失读写的机会。
因此,我们会循环从文件描述符读写数据,那么如果文件描述符是阻塞的,没有数据可读写时,进程会阻塞在读写函数那里,程序就没办法继续往下执行。
所以,边缘触发模式一般和非阻塞 I/O 搭配使用,程序会一直执行 I/O 操作,直到系统调用(如 read 和 write)返回错误,错误类型为 EAGAIN 或 EWOULDBLOCK。
|
线程怎么调度#
进程通信方法#
tcp如何保证可靠性#
https://www.cnblogs.com/kumufengchun/p/14732949.html
1
2
3
4
5
6
7
8
9
10
11
12
13
|
流量控制 是作用于接收者的,它是控制发送者的发送速度从而使接收者来得及接收,防止丢失数据包的。
TCP 利用滑动窗口实现流量控制的机制, 而滑动窗口大小是通过TCP首部的窗口大小字段来通知对方。
在TCP协议的头部信息当中,有一个16位字段的窗口大小,窗口大小的内容实际上是接收端接收数据缓冲区的剩余大小。
这个数字越大,证明接收端接收缓冲区的剩余空间越大,网络的吞吐量越大。
发送端接收到接收端的窗口变化指示后,就会对数据发送量进行调整,从而形成一个完整的流量控制。
拥塞控制 拥塞控制是作用于网络的,它是防止过多的数据注入到网络中,避免出现网络负载过大的情况
超时重传机制:
|
参考:
https://www.itzhai.com/articles/HTTP3-let-the-transmission-efficiency-take-off-again.html